|
I am currently a senior researcher at Tencent Hunyuan Team. I obtained my PhD degree at the Shanghai Jiao Tong University (SJTU), advised by Lizhuang Ma.
Looking for research interns and collaboration, feel free to contact me through the email. Email / Github / Google Scholar / Twitter |

|
|
|
(*equal contribution, ^intern)

|
Jiaqi Li^*, Junshu Tang*, Zhiyong Xu, Longhuang Wu, Yuan Zhou, Shuai Shao, Tianbao Yu, Zhiguo Cao, Qinglin Lu Technical Report, 2025 project page / paper / code |

|
Hunyuan MultiModal Model Team Technical Report, 2025 project page / paper |
|
|
Yi Chen, Sen Liang, Zixiang Zhou, Ziyao Huang, Yifeng Ma, Junshu Tang, Qin Lin, Yuan Zhou, Qinglin Lu Technical Report, 2025 project page / paper / code / demo |

|
Yufei Liu, Junshu Tang, Chu Zheng, Shijie Zhang, Jinkun Hao, Junwei Zhu, Dongjin Huang arXiv, 2024 project page / paper / code |

|
Jinkun Hao, Junshu Tang, Jiangning Zhang, Ran Yi, Yijia Hong, Moran Li, Weijian Cao, Yating Wang, Lizhuang Ma AAAI, 2025 project page / paper / code |
 
|
Yuzhou Ji, He Zhu, Junshu Tang, Wuyi Liu, Zhizhong Zhang, Yuan Xie, Lizhuang Ma, Xin Tan AAAI, 2025 project page / paper |
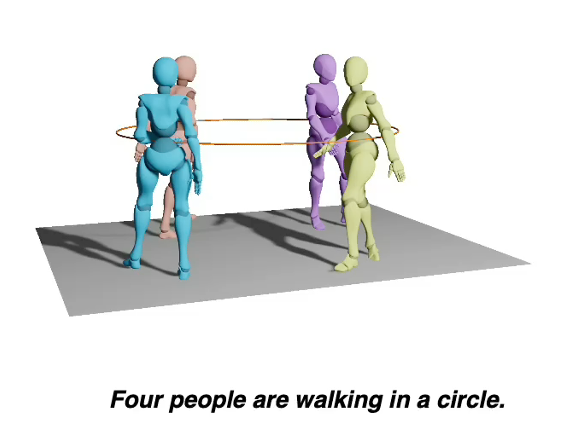
|
Ke Fan, Junshu Tang, Weijian Cao, Ran Yi, Moran Li, Jingyu Gong, Jiangning Zhang, Yabiao Wang, Chengjie Wang, Lizhuang Ma ECCV, 2024 project page / paper / code |

|
Yufei Liu, Junwei Zhu, Junshu Tang, Shijie Zhang, Jiangning Zhang, Weijian Cao, Chengjie Wang, Yunsheng Wu, Dongjin Huang ECCV, 2024, Oral project page / paper / code |

|
Junshu Tang , Yanhong Zeng, Ke Fan, Xuheng Wang, Bo Dai, Kai Chen, Lizhuang Ma CVPR, 2024 project page / paper / code |

|
Junshu Tang , Tengfei Wang, Bo Zhang, Ting Zhang, Ran Yi, Lizhuang Ma, Dong Chen ICCV, 2023 project page / paper / code |

|
Junshu Tang , Bo Zhang , Binxin Yang , Ting Zhang , Dong Chen , Lizhuang Ma , Fang Wen TVCG, 2023 project page / paper / code |
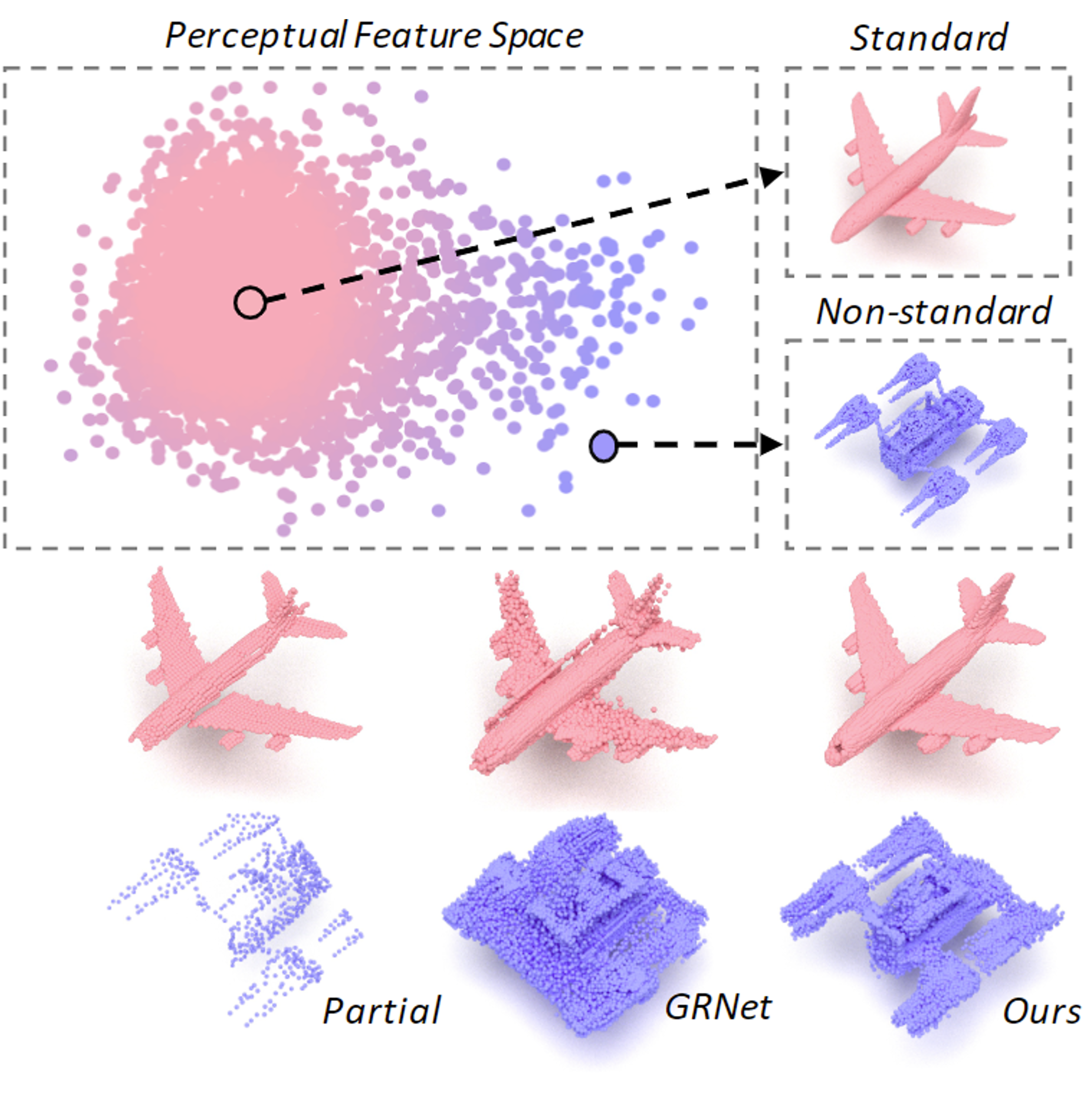
|
Junshu Tang , Jiachen Xu, Jingyu Gong, Haichuan Song, Yuan Xie, Lizhuang Ma CAD/Graphics , 2023 paper |
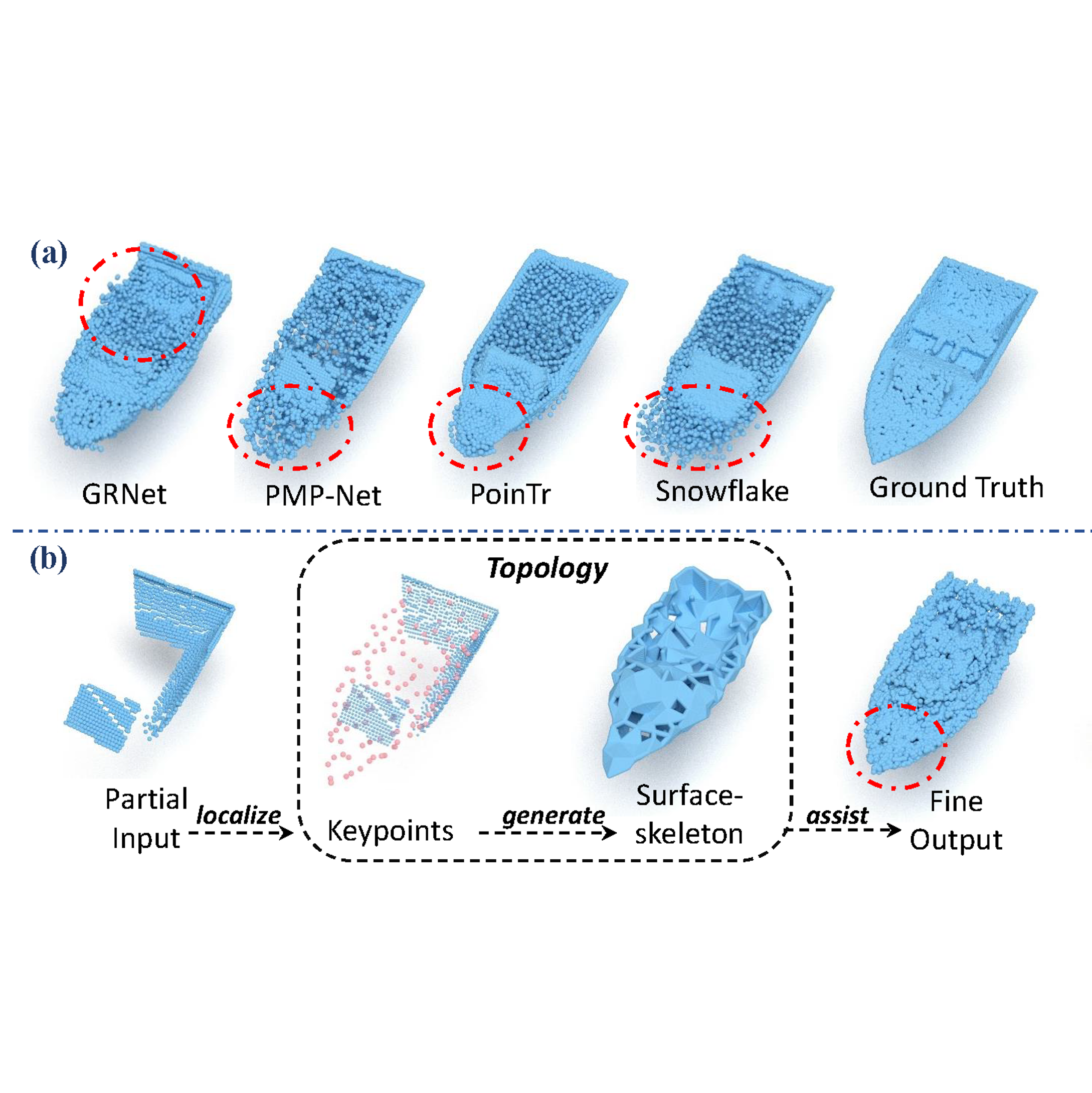
|
Junshu Tang , Zhijun Gong, Ran Yi, Yuan Xie, Lizhuang Ma CVPR, 2022 paper / code |
 
|
Zhiwen Shao, Hengliang Zhu, Junshu Tang , Xuequan Lu, and Lizhuang Ma TIP , 2021 paper |
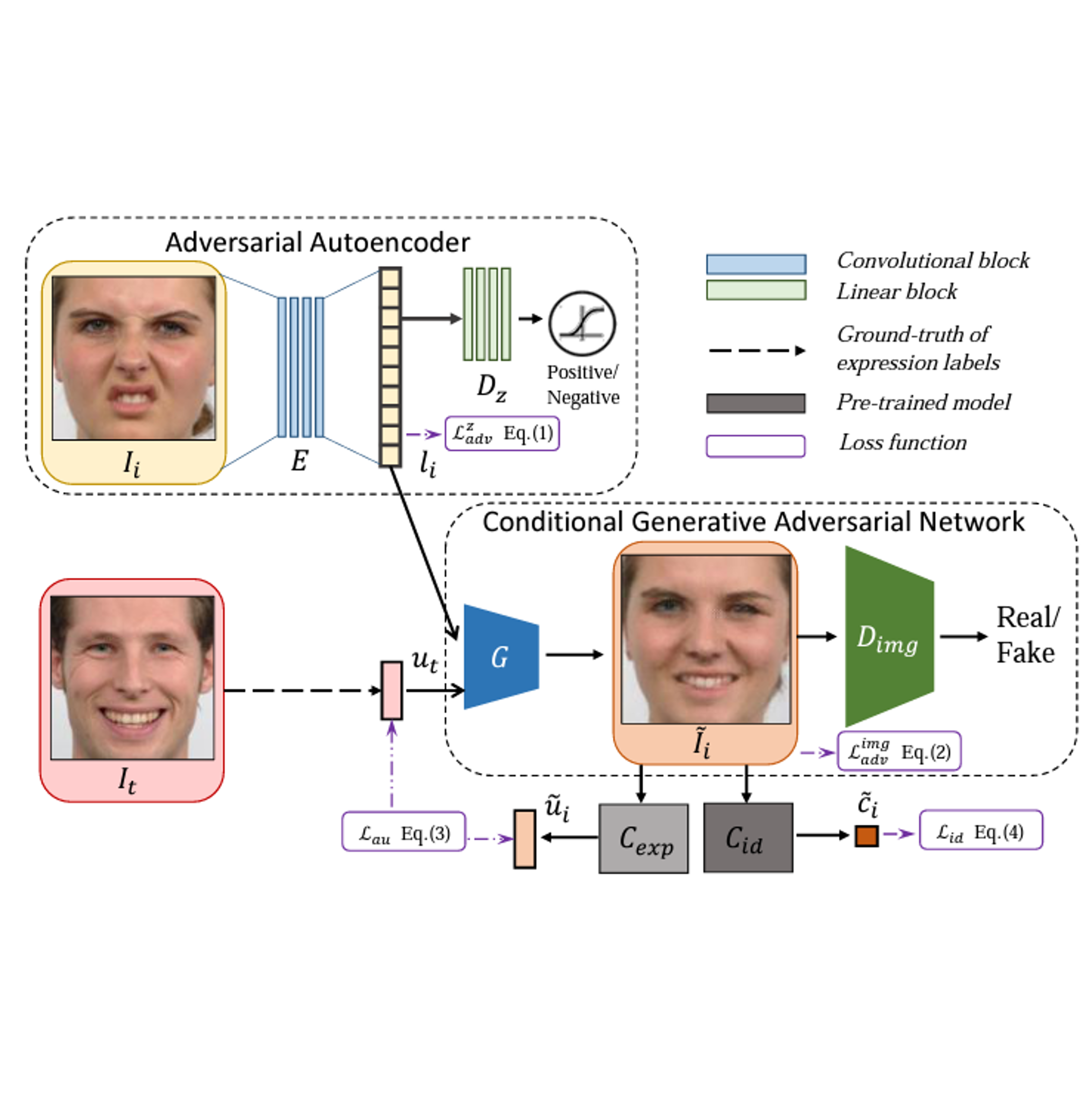
|
Junshu Tang , Zhiwen Shao, Lizhuang Ma ICME Oral Presentation, 2020 paper / code |
|
|
|
Thanks to Jon Barron for sharing the code of his personal webpage. |