Abstract
In contrast to traditional avatar creation pipeline which is a costly process, contemporary generative approaches directly learn the data distribution from photographs and the state of the arts can now yields highly photo-realistic images. While plenty of works attempt to extend the unconditional generative models and achieve some level of controllability, it is still challenging to ensure multi-view consistency especially in large poses. In this work, we propose a 3D portrait generation network that produces 3D consistent portraits while being controllable according to semantic parameters regarding pose, identity, expression and lighting. The generative network uses neural scene representation to model portraits in 3D, whose generation is guided by a parametric face model that supports explicit control. While the latent disentanglement can be further enhanced by contrasting images with partially different attributes, there still exists noticeable inconsistency in non-face areas, e.g., hair and background, when animating expressions. We solve this by proposing a radiance field blending strategy in which we form a composite output by blending the dynamic and static radiance fields, with two parts segmented from the jointly learned semantic field. Our method outperforms prior arts in extensive experiments, producing realistic portraits with vivid expression in natural lighting when viewed in free viewpoint. The proposed method also demonstrates generalization ability to real images as well out-of-domain cartoon faces, showing great promise in real applications.
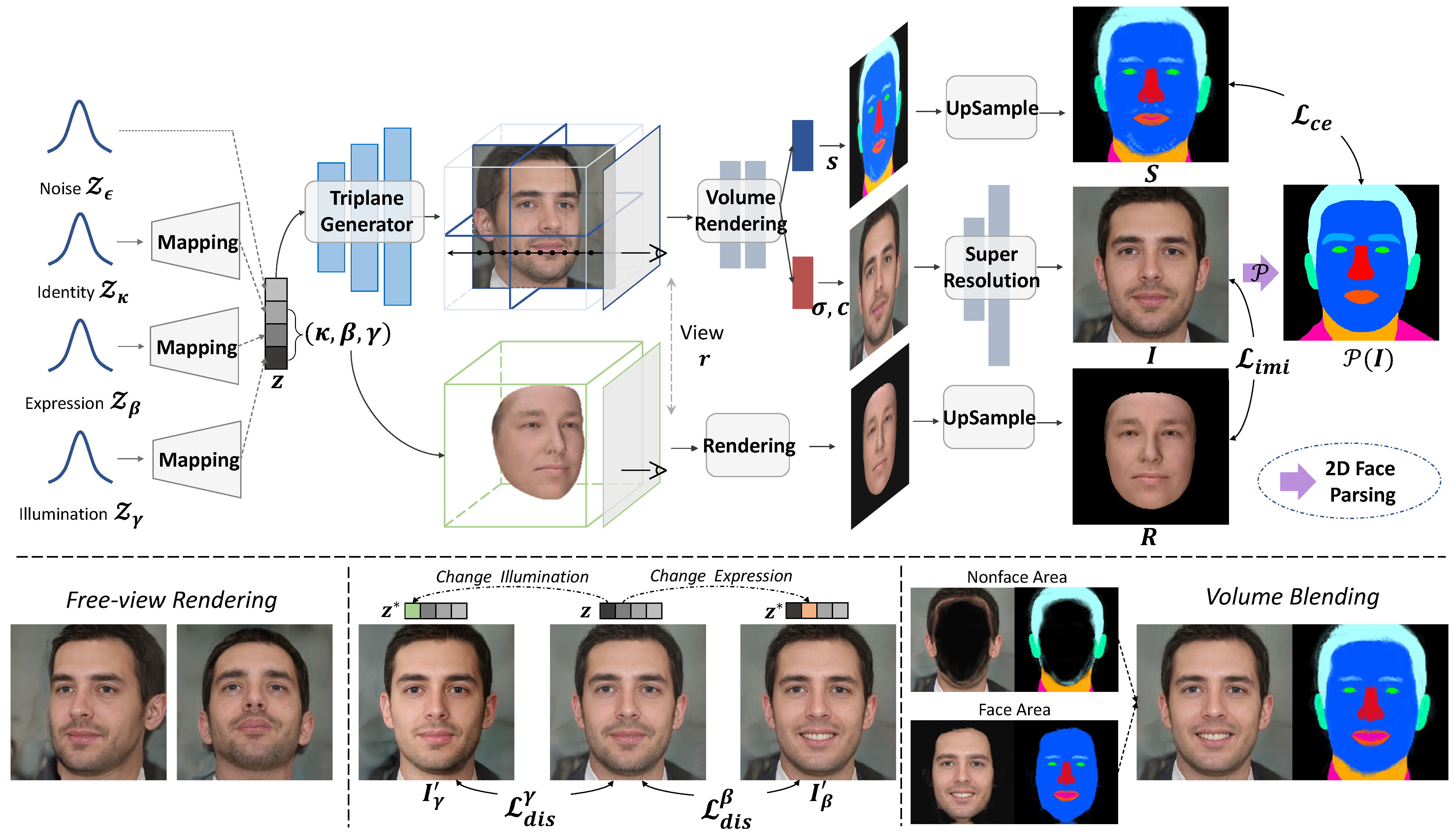
Pipeline
We aim to propose a 3D-aware GAN that allows explicit semantic control with respect to pose, identity, expression and illumination. To achieve this, we leverage a 3D-aware generator to ensure view consistency, and the generation is guided by a 3D face prior that admits semantic and interpretable control. As illustrated in the figure, the 3D-aware GAN samples from the latent space formed by a set of control parameters and the generation outputs are enforced to imitate the rendered face from the parametric face model.